上周抱着学习的心态去参加了 ECUG Con 十周年盛会,虽然大神许世伟安排了十多场有关大数据的分享。我个人认为有干货的也就2-3场,其他的要么是推销一下自己的产品(包括老许的),要么就是来打下广告招聘的(-_-!!)。其中,我认为有点干货的一场是前极光推送CTO张虎分享的:分布式系统的微服务化实践。
其中,张虎提到微服务架构中,服务发现这个实践特别重要,但是他没说有多重要。本人也曾开发过微服务框架,对微服务框架中的一些概念也有些实践,因此,我很赞同服务发现这个功能很重要,而且,我认为,这可以说是微服务框架中的核心部分。下面,就以本人的理解,对服务发现进行一些讨论,欢迎大家拍砖交流。
概述
随着软件规模的不断变大,用户的不断增加以及业务复杂度的不断增长,对于每个阶段的最优架构都渐渐不适合了,因此需要发现和发展新的软件架构。例如,从最初的CS架构到BS架构,然后又到了模块化,然后再企业总线,SOA,发展到现在流行起来了微服务。所谓的微服务其实就是将一套软件拆分为多个服务,每个服务专注于一个功能点,然后将业务流程拆分为几个不同的服务之间的组合,从而实现高内聚低耦合的效果。
但是,随着服务的不断变更,可能是机器故障原因,也有可能是服务升级需要,服务会动态得发生改变。因此,如何有效动态得维护服务就成了一个问题,最简单的需求就是当新服务节点上线要能被识别,故障服务节点下线不会再接收到任务。当然,复杂系统的服务发现组件要提供更多的功能,例如,服务元数据存储、健康监控、多种查询和实时更新等,这些都属于服务发现的范畴。
不同的使用情境,服务发现的含义也不同。例如,网络设备发现、零配置网络( rendezvous )发现和 SOA 发现等。无论是哪一种使用情境,服务发现提供了一种协调机制,方便服务的发布和查找。
服务发现的关键特性
服务发现是支撑大规模 SOA 的核心服务,它必须是高可用的,提供注册、目录和查找三大关键特性,仅仅提供服务目录是不够的。
前文已经提到过,服务元数据存储是服务发现的关键,因为复杂的服务提供了多种服务接口和端口,部署环境也比较复杂。一旦服务发现组件存储了大量元数据,它就必须提供强大的查询功能,包括服务健康和其它状态的查询。
服务发现的主要好处
服务发现的主要好处是「零配置」:不用使用硬编码的网络地址,只需服务的名字(有时甚至连名字都不用)就能使用服务。在现代的体系架构中,单个服务实例的启动和销毁很常见,所以应该做到:无需了解整个架构的部署拓扑,就能找到这个实例。
服务发现组件必须提供查询所有服务的部署状态和集中控制所有服务实例的手段。对于那些不仅提供 DNS 功能的复杂系统,这一点尤为关键。
时至今日,哪一种服务发现方案是最可靠的?
目前,业界提供了很多种服务发现解决方案。
人们已经使用 DNS 很长时间了, DNS 可能是现有的最大的服务发现系统。小规模系统可以先使用 DNS 作为服务发现手段。
- 优点:
- 实现简单,方便使用
- DNS 带缓存,大流量下问题不大
- 缺点:
- DNS 带缓存,当服务更新速度快时,刷新不实时
- 优点:
Nginx
Nginx 作为 Web 服务器,被广泛应用于各种网站,其中,很多人都以 Nginx 的反向代理功能做负载均衡,而这也是可以被应用到服务发现之中。
例如,我有一个评论服务,部署在两台机器上,分别是:- 机器A: 192.168.1.181
机器B: 192.168.1.182
那么,我们可以在 Nginx 上配置一项:
upstream comment {server 192.168.1.181:8080 weight=5;server 192.168.1.182:8080;}server {location /comment {proxy_pass http://comment;}}
这样的话,我们就可以通过访问 nginx 这台机器的
/commenturl 就可以访问服务了,也不用关心真实的服务部署在哪里,更不用关心服务是否健康,是否有多台机器提供服务。显然,这个方案好处明显,缺点也很明显,首先是优点:
- 操作简单,直接添加删除
- 可以实现动态部署和动态去除
支持权重
同时,缺点也是比较明显的
- 每次更改都需要更改 nginx 配置,当服务多了之后配置就变得很复杂了
- 所有服务调用都走 nginx,存在单点瓶颈和单点故障问题
- 无法监控服务的情况,例如服务调用频率,响应时延以及服务健康监控
服务发现框架,基于前面提到的很多原因,因此现存的软件和框架都有不适用于服务发现和注册的问题,因此,服务框架是很有必要的。以目前市场的情况来说,大部分都是基于 ZooKeeper 来构建的,Zookeeper 目前来说,可以说是最成熟的配置存储方案,它的历史比较长,提供了包括配置管理、领导人选举和分布式锁在内的完整解决方案。因此, ZooKeeper 是非常有竞争力的通用的服务发现解决方案,当然,它也显得过于复杂。
因此
etcd和doozerd是新近出现的服务发现解决方案,它们与ZooKeeper具有相似的架构和功能,因此可与 ZooKeeper 互换使用。本文也是以 etcd 为配置管理组件,来介绍服务发现框架的设计。
服务发现框架设计
根据之前的描述,这里就谈谈如何设计一个服务发现框架,首先,我们需要明确的标准就是,我们需要这个服务发现框架具备什么功能?这里简单列举一下:
- 服务上线可以自动注册
- 服务下线消费者可以感知并不使用下线服务
- 服务调用情况可以监控,包括调用次数,调用路径
本节就以这三个目标为基础,结合 etcd 组件展开介绍。首先,我想先介绍一下我是如何在 etcd 中组织服务结构的,这里的数据结构我是这样处理的:
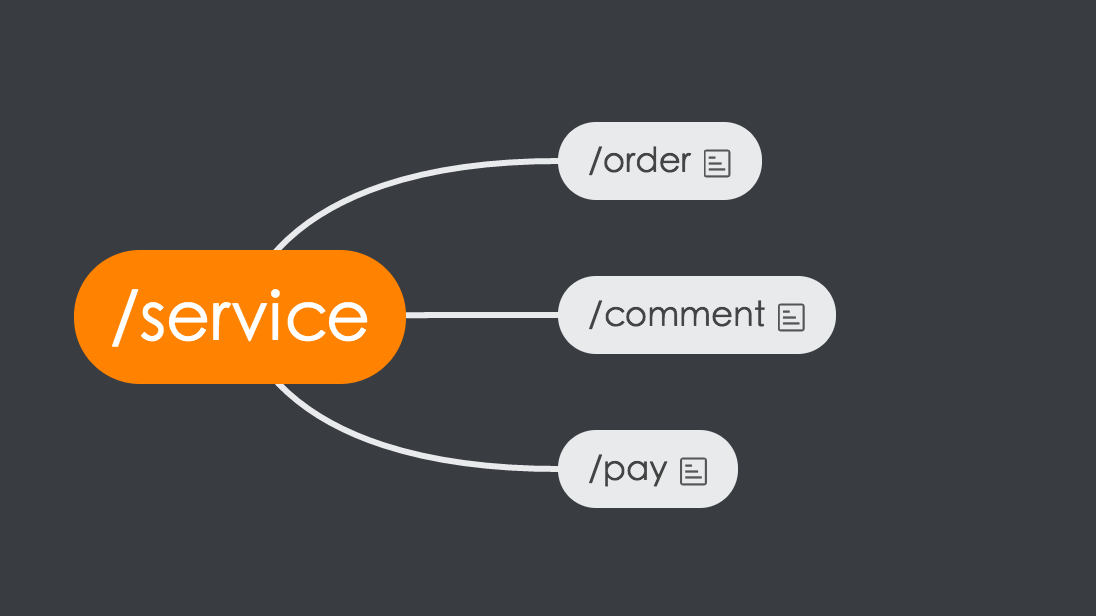
可以发现在节点上是有存放数据的,里面存放的数据结构是这样的:
type Service struct {Name stringDesc ServiceDescNodes Cluster}type ServiceDesc struct {Type stringHost stringPort intBlockTime intBlockInterval intBlockTokenCnt int}type Cluster []EndpointDesctype EndpointDesc struct {Host stringPort intWeight int}
这是一个 Golang 的数据结构定义形式,可以发现每个节点里面,我们存放了服务的名称、服务的元数据以及服务的节点数据,数据结构已经给出了,那么我们就以这份数据结构为出发点,看看如何实现满足我们需求的服务发现框架。
- 服务上线可以自动注册
要想实现这个需求从我们这份服务表里面是实现不了的,这个应该放在服务框架中实现,具体实现的时候,我们可以让服务在启动完毕之后,自动往 etcd 的对应节点上插入自己的节点数据,例如 comment 服务上线之前,我们的 etcd 上的 /service/comment 节点的数据为:
{"Name": "comment","Desc": {"Type": "HTTP","Host": "127.0.0.1","Port": 10001,"BlockTime": 0,"BlockInterval": 0,"BlockTokenCnt": 0},"Cluster": [{"Host": "192.168.1.181","Port": 8080"Weight": 5}]}
上线一个新的节点 192.168.1.182:8080 之后,我们的节点可能就变成了这样了:
{"Name": "comment","Desc": {"Type": "HTTP","Host": "127.0.0.1","Port": 10001,"BlockTime": 0,"BlockInterval": 0,"BlockTokenCnt": 0},"Cluster": [{"Host": "192.168.1.181","Port": 8080"Weight": 5},{"Host": "192.168.1.182","Port": 8080"Weight": 10}]}
这样的话,我们就将 192.168.1.182:8080 这台机器注册为 comment 服务了。
- 服务下线消费者可以感知并不使用下线服务
这个功能其实我们的服务发现也并不能帮助太多,那么就将这个功能交给消费者来做,当消费者需要服务的时候会从 etcd 中寻找服务节点,并且根据权重选择服务节点。一旦发现选中的服务节点不可用,那么消费者就可以修改这个注册中心节点,从而使这个节点不被使用。
- 服务调用情况可以监控,包括调用次数,调用路径
其实 2 中的方案会有较大的问题,就是如果一个服务因为一些原因挂掉之后,但是,过了一段时间又变好了,那么会自动加回服务列表中去么?这个依赖于我们的服务框架的实现,我们在设计服务框架的时候必须考虑到这个问题 —— 服务的健康监控。其次的话,就是我们需要梳理出我们的业务的关键路径,也就是说虽然我们的架构中可能有几十个服务,但是,二八原则告诉我们,可能事实上只有 20% 的服务是被经常使用的,对于这些服务我们需要额外关注,并且加大容量。那么如何识别出这 20% 的服务呢,这就依赖于我们的服务功能,我们可以在服务框架中加入服务调用监控的功能,每个服务被调用的时候都能上报调用信息,并且最好是能够结合到数据分析平台中,这样的话,我们就能实现很多功能,例如关键服务识别,关键业务路径等。
总结
本文就以微服务中的服务发现这一主题进行了简单介绍,并且给了一个实现思路,虽然说的是服务发现这个主题,但是事实上提到的内容涵盖了微服务的多个方面。本人关于微服务的流派是参考 Martin Fowler 的观点,可能每个人对于微服务的理解都不完全一样,但是,目的都差不多,都是为了解决企业应用复杂度的问题,如何实现高内聚低耦合的问题。我非常欢迎不同想法的碰撞,如果有关微服务的各种意见,欢迎留言交流,感谢阅读本文。