updated at:2020-01-05 22:55
下面有同学评论推荐使用 pandas,我个人没有试验过,据说还不错。
updated at: 2023-06-10 16:38
最近又想要读取 excel,所以又尝试了一下 pandas,果然比较简单,这里顺便做了一个记录。
概述
python 读写 excel 有好多选择,但是,方便操作的库不多,在我尝试了几个库之后,我觉得两个比较方便的库分别是 xlrd/xlwt、openpyxl。之所以推荐两个库是因为这两个库分别操作的是不同版本的 excel,xlrd 操作的是 xls/xlxs 格式的 excel,而 openpyxl 只支持 xlxs 格式的 excel,openpyxl 使用起来会更方便一些,所以如果你只操作 xlxs 文件的话,那么可以优先选择 openpyxl,如果要兼容 xls 的话,那就用 xlrd/xlwt 吧。
excel 概念
在开始介绍库之前,如果你不是很熟悉 excel,我这里简单介绍一些关于 excel 的概念,如果你对 execl 已经很熟悉的话,可以跳过。
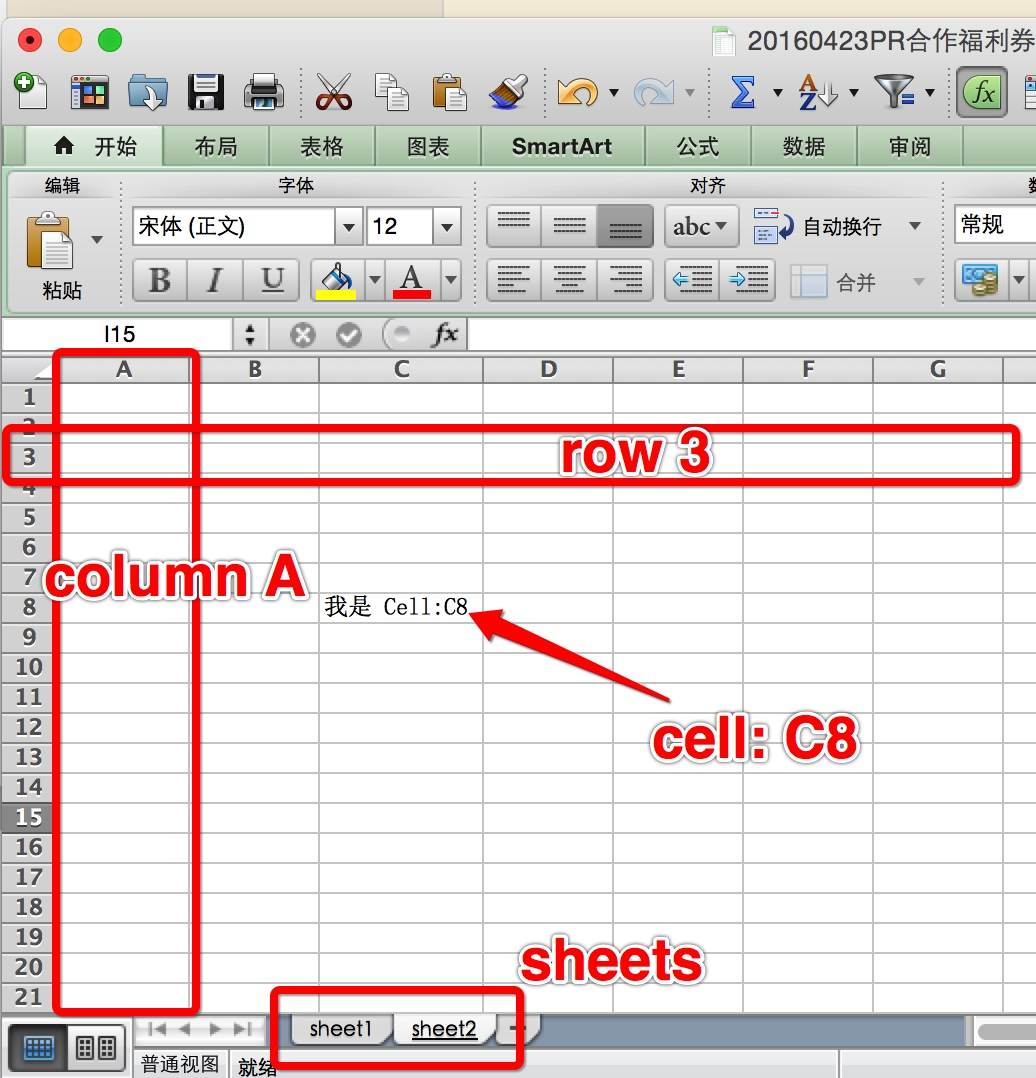
- workbook: 在各种库中,workbook 其实就是一个 excel 文件
- sheet: 在一个 excel 文件中,可能会有多个 sheet,一个 sheet 可以看做一张表
- row: row 其实就是一张表中的一行,正常是用数字 1、2、3、4 表示
- column: column 就是一张表中的一列,正常用字母 A、B、C、D 表示
- cell: cell 就是一张表中的一格,可以用 row + column 的组合来表示,例如: A3
综合起来,我们可以用这张图来表示各个概念:
| 图 1:Excel 概念 |
|---|
|
介绍 excel 的基本结构之后,我们就来看下怎么用 python 的开源库来操作 excel。
xlrd/xlwt
xlrd/xlwt 读写 xls
因为 xlrd 是只能用来读取 excel 的,所以我们还需要用 xlwt 来写出 excel。
安装 xlrd 和 xlwt
xlrd 和 xlwt 都可以通过 pip 直接安装。
[root@liqiang.io]# pip install xlrd xlwt
读取 excel
假设我的 excel 内容如下:
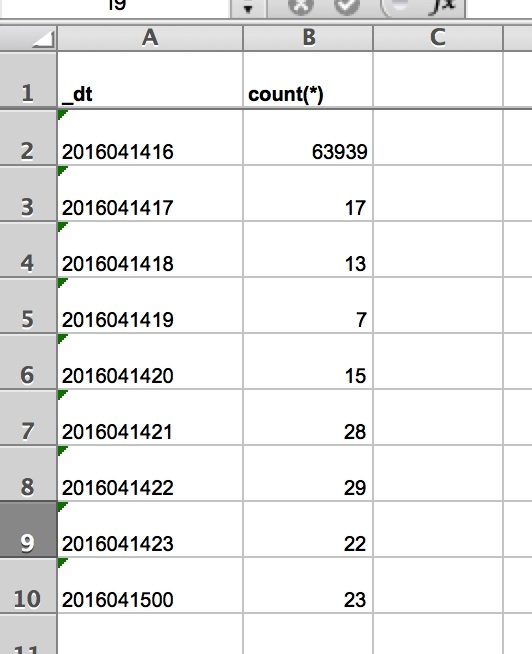
那么,我要将数据遍历出来,那么代码可以这样实现:
import xlrd# 打开excel 文件data = xlrd.open_workbook('query_result.xls')# 通过名称获取工作表table = data.sheet_by_name(u'Tablib Dataset')# 获取表格的行数和列数nrows = table.nrowsncols = table.ncolsfor i in range(nrows):# 获取一行的数据,返回数组row_values = table.row_values(i)for i in range(ncols):print row_values[i]
这里用了稍微高效一点点的方法来操作数据,其实获取 cell 的值还有几种方法,例如,直接获取指定位置的 cell 的值可以这样写:
# 用table直接获取单元格的值cell_A1 = table.cell(0,0).valuecell_C4 = table.cell(2,3).value
也可以这样来:
# 使用行列索引来获取值cell_A1 = table.row(0)[0].valuecell_A2 = table.col(1)[0].value
写出 excel
假设我们有这样一组数据要写出到 excel
| 姓名 | 性别 | 年龄 | 身高 | 体重 |
|---|---|---|---|---|
| 张三 | 男 | 18 | 166 | 60 |
| 李四 | 未知 | 未知 | 177 | 88 |
那么,这里就使用 xlwt 来写出到 excel,直接上代码,代码里面加注释:
import xlwt# 创建工作簿f = xlwt.Workbook()# 创建一个 user_info 的 sheetsheet1 = f.add_sheet(u'user_info',cell_overwrite_ok=True)rows = [['姓名', '性别', '年龄', '身高', '体重'],['张三', '男', '18', '166', '60'],['李四', '未知', '未知', '177', '88']]for i in xrange(len(rows)):row = rows[i]for j in xrange(len(row)):# 以 cell 为单位写出单元格sheet1.write(i, j, rows[i][j])# 别忘了保存f.save('/Users/imaygou/Code/test/test.xls')
一些问题
- 读取excel中单元格内容为日期的方式
python读取excel中单元格的内容返回的有5种类型,即ctype:
ctype : 0 empty, 1 string, 2 number, 3 date, 4 boolean, 5 error
默认读取的时间为:
>>> sheet2.cell(2,2).value #1990/2/2233656.0
设置一下读取的时间为:
>>> xlrd.xldate_as_tuple(sheet2.cell_value(2,2),workbook.datemode)(1992, 2, 22, 0, 0, 0)
可以抽成一个函数一个函数的:
def convert_date(sheet, row, col):data = sheet.cell(row,col)if (data.ctype == 3):date_value = xlrd.xldate_as_tuple(sheet.cell_value(rows,3),book.datemode)data = date(*date_value[:3]).strftime('%Y/%m/%d')return data
读取合并单元格的内容
这个是真没技巧,只能获取合并单元格的第一个cell的行列索引,才能读到值,读错了就是空值。
获取合并的单元格
读取文件的时候需要将formatting_info参数设置为True,默认是False,所以上面获取合并的单元格数组为空,
>>> workbook = xlrd.open_workbook(r'F:demo.xlsx',formatting_info=True)>>> sheet2 = workbook.sheet_by_name('sheet2')>>> sheet2.merged_cells[(7, 8, 2, 5), (1, 3, 4, 5), (3, 6, 4, 5)]
merged_cells返回的这四个参数的含义是:(row,row_range,col,col_range),其中 [row,row_range)包括 row,不包括 row_range,col 也是一样,即 (1, 3, 4, 5) 的含义是:第 1 到 2 行(不包括3)合并,(7, 8, 2, 5)的含义是:第 2 到 4 列合并。
pandas
安装
[root@liqiang.io]# pip install pandas xlrd
使用
[root@liqiang.io]# cat test.pyimport pandas as pd# 加载.xls文件data = pd.read_excel('./scripts/test.xls')print(data)for index, row in data.iterrows():print(row['ColumnName'], row[0])